Document Hierarchies for RAG in GenAI
A document hierarchy is a powerful way of organizing your data to improve information retrieval. It organizes chunks in a structured manner that allows RAG systems to efficiently retrieve and process relevant, related data. Document hierarchies play a crucial role in the effectiveness of RAG by helping the LLM decide which chunks contain the most relevant data to extract.
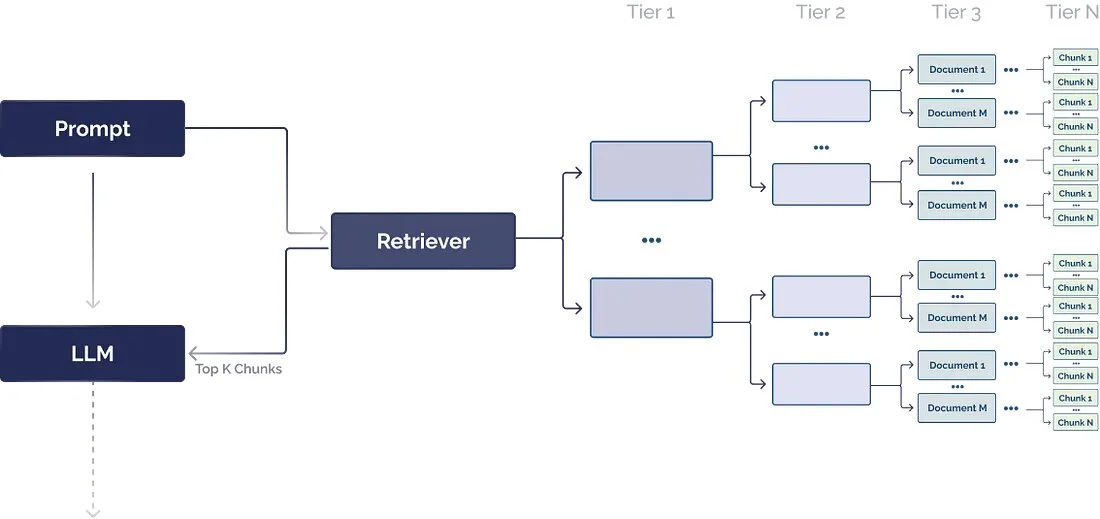
Document hierarchies associate chunks with nodes, and organize nodes in parent-child relationships. Each node contains a summary of the information contained within, making it easier for the RAG system to quickly traverse the data and understand which chunks to extract.
Why would you need a document hierarchy if an LLM supposedly is able to understand the words in a document?
Although the LLM can extract relevant chunks of text from a vector database, you can improve the speed and reliability of retrieval by using a document hierarchy as a pre-processing step to locate the most relevant chunks of text. This strategy improves retrieval reliability, speed, repeatability, and can help reduce hallucinations due to chunk extraction issues. Document hierarchies may require domain-specific or problem-specific expertise to construct to ensure the summaries are fully relevant to the task at hand.
Let’s take a use case in the HR space. Let’s say that a company has 10 offices and each office has their own country-specific HR policy, but uses the same template to document these policies. As a result, each office’s HR policy document has roughly the same format, but each section would detail country-specific policies for public holidays, healthcare, etc.
In a vector database, every “public holiday” paragraph chunk would look very similar. In this case, a vector query could retrieve a lot of the same, unhelpful data, which can lead to hallucinations. By using a document hierarchy, a RAG system can more reliably answer a question about public holidays for the Chicago office by first searching for documents that are relevant to the Chicago office.
It should become increasingly clear that most of the work that goes into building a RAG system is making sense of unstructured data, and adding additional contextual guardrails that allow the LLM to make more deterministic information extraction.