RPA (Robotic Process Automation) with OCR (Optical Character Recognition) as DATA EXTRACTOR
OCR (Optical Character Recognition) with RPA (Robotic Process Automation) is a combination of technologies used to automate the extraction and processing of data from scanned documents, images, or PDFs. OCR technology converts different types of documents, such as hand written documents, scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data.
Below image shows that the data extracted from the pdf using robotic process automation(RPA) with the help of optical character recognition(OCR) can store results in various persistance like CSV, Database, Messaging System, etc.

Features of RPA with OCR:
-
Text Recognition:
-
Converts printed or handwritten text into machine-readable text.
-
Supports multiple languages and text styles.
-
-
Data Extraction:
-
Identifies and extracts specific fields or patterns, such as dates, numbers, or predefined text segments.
-
Capable of extracting data from structured, semi-structured, and unstructured documents.
-
-
Integration with RPA:
-
Seamlessly integrates with RPA tools to automate the workflow of data processing.
-
Can trigger subsequent automated processes based on the extracted data.
-
-
Machine Learning and AI:
-
Utilizes machine learning models to improve accuracy over time through continuous learning.
Employs AI to understand context and improve data extraction from complex documents.
-
-
Validation and Error Handling:
-
Includes mechanisms for validating extracted data against predefined rules.
-
Provides error handling and exception management to ensure data integrity.
-
Process Flow
Here is a simplified diagram to visualize the process flow of OCR with RCA:
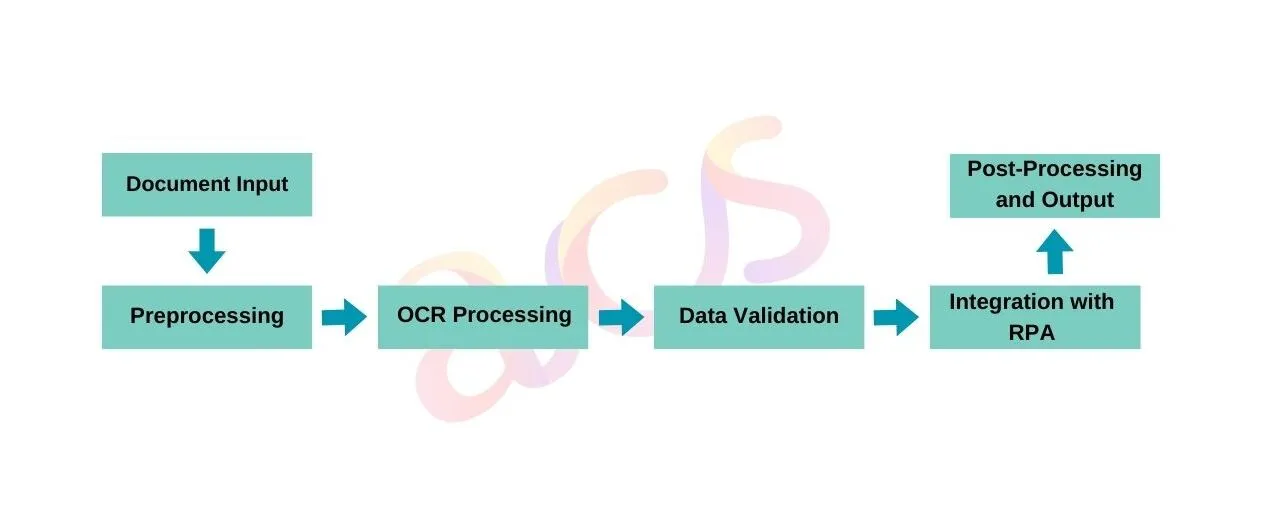
1. Document Input: Collection of documents from various sources (scanned papers, images, PDFs).
2. Preprocessing: The Conversion of images to a standard format suitable for OCR processing.
3. OCR Processing: Application of OCR algorithms to convert images into machine-readable text.
4. Data Validation: Correction of errors and handling exceptions if the extracted data does not meet validation criteria.
5. Integration with RPA: Triggering of RPA bots to further process the validated data.
6. Post-Processing and Output: Formatting and structuring the extracted data for final output and exporting data to desired formats (e.g., CSV, Excel, databases) or directly into business applications.
